All data should be permissioned data

My post with vague complaints about the proposal that daniel holmgren 🫠 made for permissioned data got a bit of attention. Daniel was kind enough to take the time to chat with me, and I wanted to provide some more fulsome thoughts as a result of that conversation. (To be clear, these are my thoughts; I'm not claiming that Daniel agrees with them!)
tl;dr: If permissioned data is worth doing, it's worth doing for everything. Public data like we have today should be a special case. We should design the system as if we're headed in that direction. In particular, the deniable cryptography currently in the proposal should be dropped.
The core ideas make sense
The basics of permissioned data are as follows:
- The unit of permissioned data is a space, which is logically a collection of records.
- A space has an owner. The owner decides who are the legitimate readers and writers in the space.
- Anyone can claim to write records into the space by creating a repo on their PDS tagged as belonging to the space and writing into that repo.
- To read records from a space-tagged repo, a client obtains a space credential from the owner and presents it to the PDS (which access-controls the data).
This is a reasonable first step on which more complex schemes can be built. Policy distribution is centralized at the owner, but policy definition could be decentralized behind it; policy enforcement is already decentralized. There are some details to be worked out (I don't love the member-list stuff), but those should be doable.
Even though my initial reaction was that we shouldn't tie in "data for me" with the broader permissioned data design, I can see how that makes sense in this scheme: A "data for me" repo is just a trivial case where the author is the owner and the only authorized reader/writer.
Public data is a special case of permissioned data
You know what else is a trivial case? A public repo like we have today! The author is the owner and the only authorized writer, and everyone's an authorized reader. Maybe we should recognize that single-public-repo-per-DID was a useful transitional step, and migrate toward a world where each author can have multiple repos with various permissions policies.

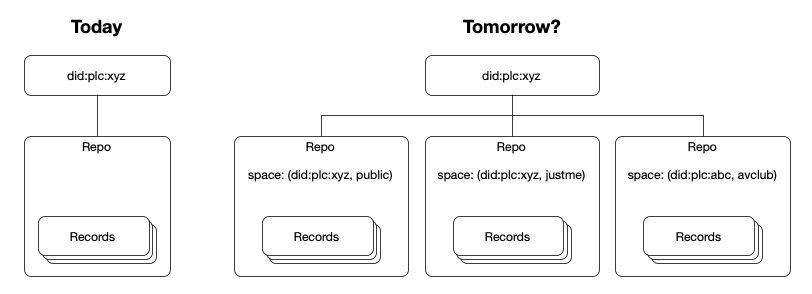
In a sense, this is unavoidable. The permissioned data scheme is already trying to address (a) spaces with a single author and (b) spaces where everyone can read. If you put those together, you get a public repo.
Using the same scheme for public data and data with other permissions would keep the logic and data structures more unified, allowing both types of data to benefit from future developments in the protocol. Public data could benefit from having multiple repos, e.g., to segregate record types as is currently done downstream. Private data might be able to benefit from current designs for aggregation and caching (carefully; more on this below).
With all that said, there are a few potential drawbacks to this scheme, none of which I think need to be blockers.
Access control overhead — As things are defined now, a relay or app view consuming lots of public repos would have to go get specific space credentials for each one. That's obviously a lot of hassle, but it can also be optimized out simply by having some flag on the repo that says "everyone is allowed to read this data". That's also a useful optimization for openly readable permissioned spaces.
Selection among public repos — If a given author can have multiple public repos, then it might not be clear which ones a relay / app view needs to sync or otherwise interact with. As noted above, this is a problem that will arise regardless of whether legacy repos use the new structure. And maybe it's not a problem: Maybe all public repos should be synced around just like the ones we have today.
Redistribution (or not) of permissioned repos — Obviously, there are a lot of risks involved in aggregation and caching of repos with non-trivial access control policies. Anyone redistributing permissioned data also needs to apply the access control policy. The right answer is probably to omit permissioned repos from redistribution schemes for now, leaving access-controlled redistribution for future study. For example, it could work well for the space owner to act as a redistribution point.
Deniability — The proposal spends an inordinate amount of time defining a completely new cryptographic structure for permissioned data, removing signatures and Merkle trees in the interest of one goal: deniability. Reasonable people can disagree on this, but it seems to me that this is a ton of work and incompatibility for negligible benefit, and should all be scrapped. The scenario that deniability addresses is: If someone inside the group leaks permissioned data to someone outside the space, can they prove whether the data is authentic? Experience shows that when leaks like this happen, cryptography just isn't a major factor; see the DNC emails vis à vis DKIM or Signalgate with Signal, and of course the innumerable breaches where no cryptographic proof is available. At best, the black market gets a little more efficient by virtue of the ultimate customer of the data having less trust in the infiltrator middleman.
Keep the at: URI scheme
I mentioned in my original post that the ats: URI scheme has a bad smell, and I continue to believe that. The figure above clarifies where the real change is needed. An at: URI has two parts: A identifier for a repository and an identifier for a record within a repository.
The reason at: gets uncomfortable for permissioned data is that it assumes that there is exactly one repo per DID. The solution is update the URI scheme so that it has separate notions for those two things, either by replacing the current DID slot with something that actually represents the repo (basically, DID + space), or by adding a slot after the DID that specifies the repo.

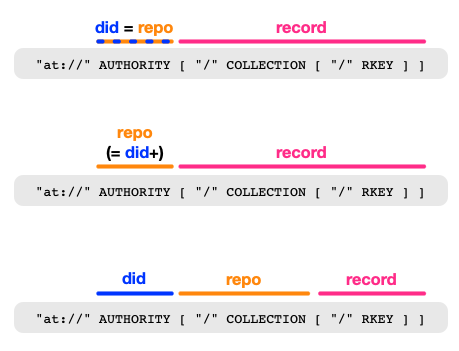
I would probably tend toward the latter, since the DID is ultimately the authority. The DID tells you what PDS to go to and how to verify the data you get back. The stuff to the right of the authority/DID tells you what to request from the PDS.
Let's do this
I'm really glad to see a concrete proposal here, especially one that seems to meet a number of use cases expressed by the community in a pretty compact framework. There are still some details to be worked out, and I'm hopeful that things will get even simpler still.
One question that a couple of folks have asked me (as someone experienced with IETF) is whether this should be done in the IETF ATP working group. My reaction is basically, "Not now, but eventually". On the one hand, it's generally not good form to both have an IETF working group and do new work elsewhere. On the other hand, it is good to keep the IETF group focused on its charter, and it's fine to incubate stuff elsewhere until we have enough confidence to start nailing it down. Net of all that and the URI comments above, it would be good to get make sure URI scheme is forward-compatible with what we need here, and otherwise just have an eye towards bringing the permissioned data structure into the IETF once it's a little more baked.
Either way, excited to see where this goes!
Sign in to leave a note.